PickFlix — Repenser la recommandation cinématographique en milieu rural grâce à la data

📌 Contexte & Problématique
Dans le cadre de ma formation en Data Analyse, j’ai réalisé un projet intitulé PickFlix, dans lequel je me suis glissé dans la peau d’un Data Analyst freelance. Ma mission : aider un cinéma local de la Creuse, en perte de vitesse, à faire un virage digital.
Le client voulait offrir un outil en ligne de recommandation de films personnalisé à ses spectateurs, en parallèle de son site Internet. L’enjeu ? Créer un moteur de recommandations intelligent, sans disposer au départ d’aucune préférence client (situation de cold start).
🗺️ Étape 1 – Étude de marché (Semaine 1 & 2)
Avant de plonger dans les bases de données, il était essentiel de comprendre le public local :
📊 Analyse démographique de la région Creuse (via les données INSEE)
🎟️ Recherche sur la consommation cinématographique en milieu rural (CNC)
🧠 Identification des préférences cinématographiques locales et nationales
📚 Synthèse des données et présentation des conclusions
👉 Cette première phase a permis d’identifier des genres de films préférés, de dégager les habitudes de consommation, et de guider la suite de l’analyse.

🧹 Étape 2 – Appropriation et traitement des données (Semaine 3)
Le client nous a fourni un jeu de données massif basé sur IMDb et complété par TMDB, ce qui représentait plusieurs millions de lignes.
Les étapes techniques :
🔍 Exploration initiale des datasets IMDb
🧼 Nettoyage et filtrage des données : suppression des doublons, valeurs manquantes, typage
🔗 Jointures entre les tables (films, acteurs, réalisateurs)
📦 Export de jeux de données allégés pour traitement futur
Cette phase a été l’occasion de consolider ma maîtrise de Pandas et de travailler avec des fichiers volumineux au format TSV.
📊 Étape 3 – Analyse exploratoire & visualisations (Semaine 4)
Objectif : dégager des tendances pour alimenter le système de recommandation.
J’ai notamment réalisé des analyses sur :
🧑🎬 Les acteurs les plus présents et leurs périodes d'activité
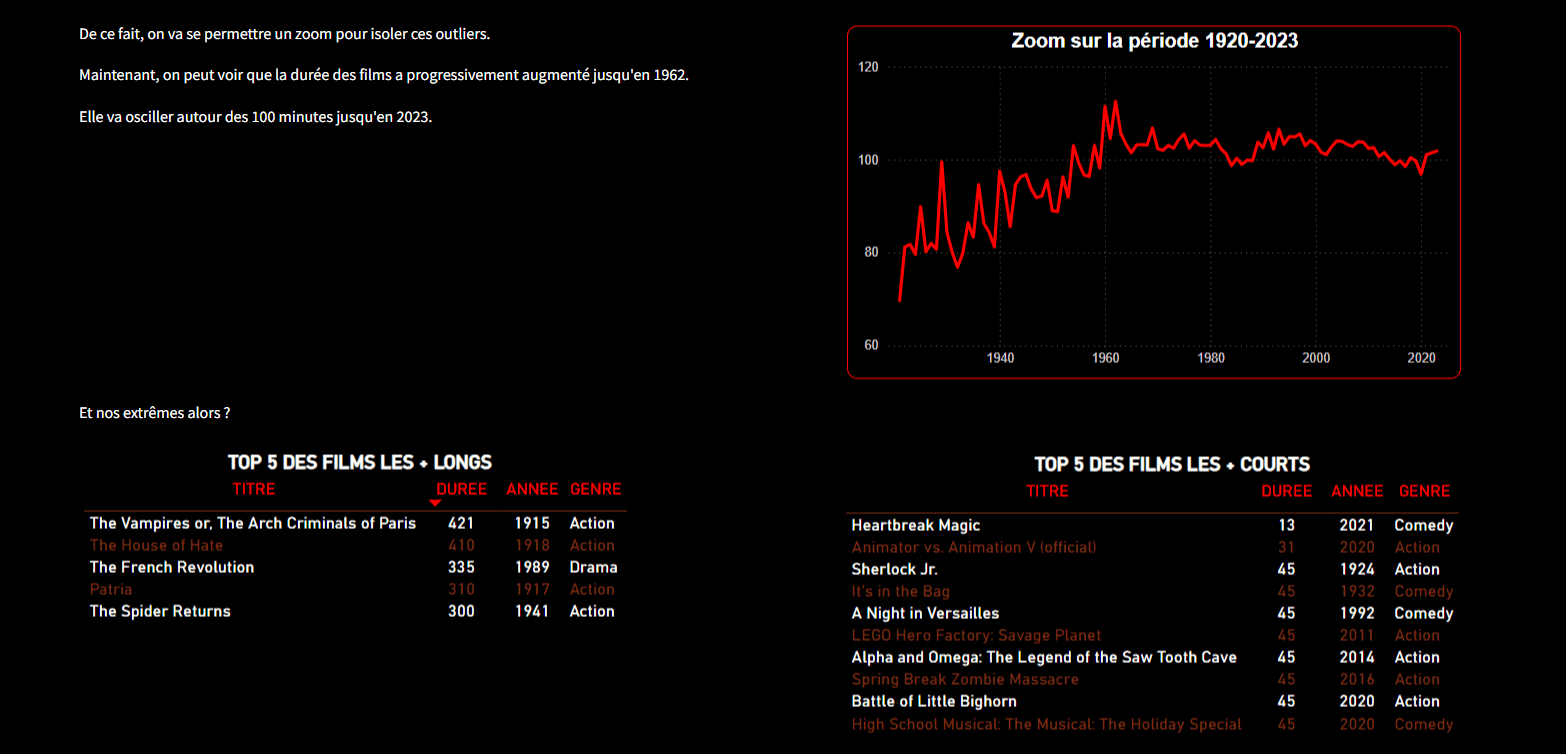
📈 L’évolution de la durée moyenne des films
👵 L’âge moyen des acteurs par genre
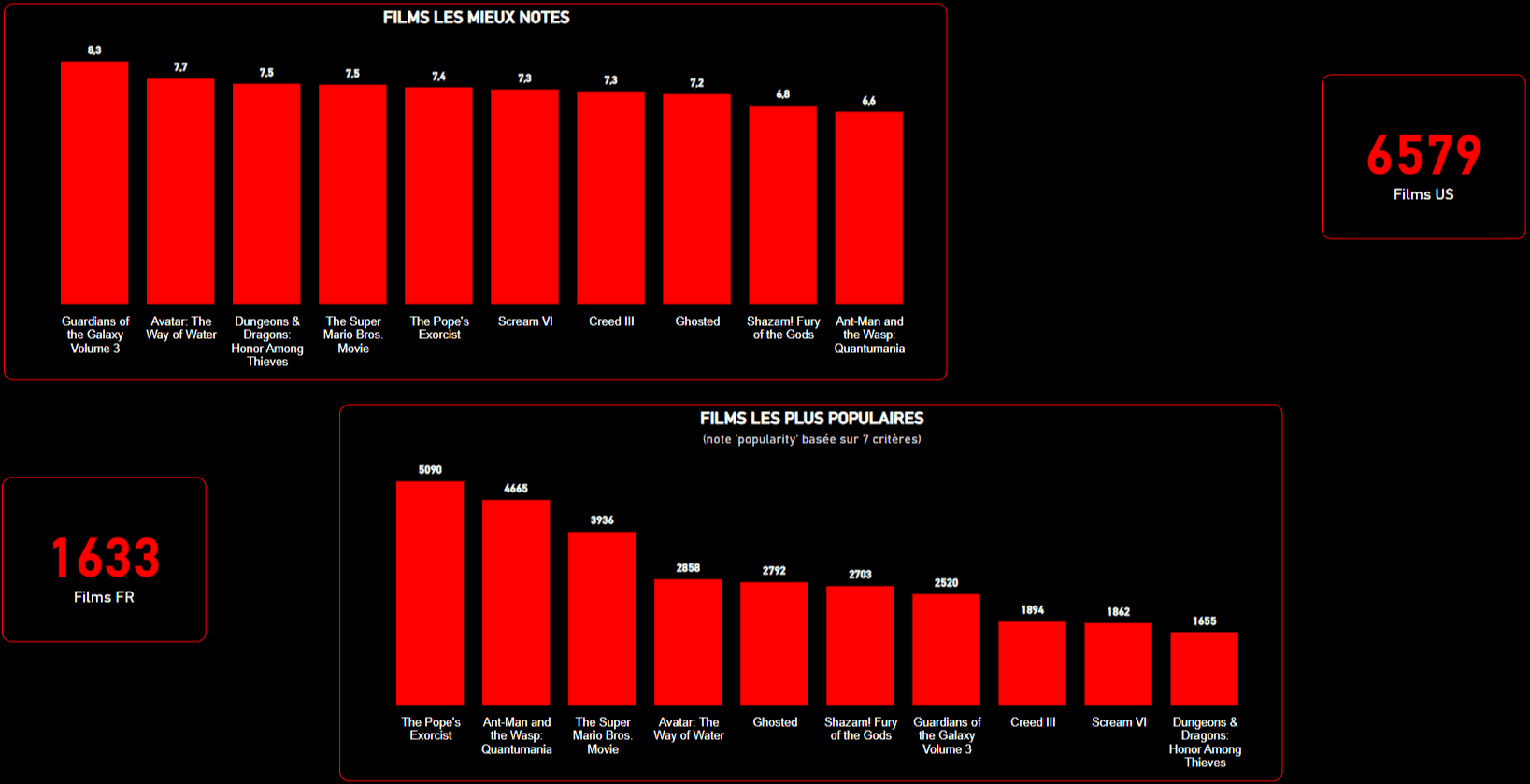
🌟 Les films les mieux notés et les caractéristiques partagées
Le tout a été synthétisé dans des visualisations interactives pour un futur dashboard. Cette phase m’a permis de poser des hypothèses sur les préférences du public rural.
🧠 Étape 4 – Machine Learning et recommandations (Semaines 5 & 6)
Cœur du projet : créer un système de recommandation basé sur le contenu à partir de films appréciés.
📂 Préparation des données d'entraînement
🧪 Test d’un premier modèle avec Scikit-Learn (KNN)
🔄 Intégration de la récupération des posters de films via TMDB
🤝 Ajout d’un second modèle : filtrage collaboratif simplifié
🛠️ Optimisation et validation finale du système
👉 Le modèle renvoie désormais une liste de films similaires à un titre saisi par l’utilisateur.
💻 Étape 5 – Interface utilisateur & dashboard final (Semaine 7)
Pour que le client puisse tester la solution, j’ai développé une application interactive sous Streamlit :
📈 Un tableau de bord présentant les KPIs clés sur les films et les acteurs
🔍 Un moteur de recherche permettant de taper un film et d’obtenir des recommandations
🖼️ Affichage des posters des films recommandés
🔁 Un bouton “Accueil” pour revenir à l’état initial
🎯 Cette interface simple et responsive peut être intégrée ou liée au site du cinéma.
🔗 Lien vers l’application finale : https://pickflix.streamlit.app
🧠 Ce que j’ai appris
Gérer des datasets massifs (90M+ lignes) de manière efficace
Maîtriser les jointures complexes entre tables relationnelles
Implémenter un système de recommandation en situation de cold start
Créer un dashboard interactif et orienté utilisateur
Adapter mon approche aux besoins d’un client réel
🔮 Pistes d'amélioration
Intégrer les préférences utilisateur une fois collectées (filtrage collaboratif plus robuste)
Ajouter des critères personnalisés (budget, pays, langue)
Optimiser les performances de l’interface
Déployer l’application sur un hébergeur pour usage réel
🧰 Stack technique utilisée
Python, Pandas, Matplotlib, Seaborn
Scikit-Learn (KNN), NLP pour le contenu
Streamlit pour l’interface
IMDb & TMDB datasets (TSV & CSV)
💬 Conclusion
Ce projet m’a permis de lier data analyse, machine learning, et UX pour répondre à un besoin concret. À travers PickFlix, j’ai pu allier technique et sens produit pour proposer une solution digitale innovante à un acteur local du cinéma.